北理工團隊在遙感多模態(tài)大語言模型研究方面取得重要進展
發(fā)布日期:2024-06-21 供稿:前沿交叉科學研究院 攝影:前沿交叉科學研究院
編輯:楊婧 審核:陳棋 閱讀次數(shù):
2024年5月,北京理工大學前沿交叉學院數(shù)據(jù)流體課題組近日在遙感多模態(tài)大語言模型研究中取得重要進展,相關成果以“EarthGPT: A Universal Multi-modal Large Language Model for Multi-sensor Image Comprehension in Remote Sensing Domain”為題發(fā)表在國際頂級期刊《IEEE Transactions on Geoscience and Remote Sensing (TGRS)》上發(fā)表。北京理工大學為唯一通訊單位,北京理工大學前沿交叉學院博士張偉和雷達技術(shù)研究院博士蔡妙鑫為共同第一作者,毛雪瑞教授為通訊作者。
目前遙感領域視覺模型大多都遵循“一任務一架構(gòu)”的范式,使得這些專才模型無法在同一架構(gòu)下統(tǒng)一處理多模態(tài)圖像和多任務推理。最近,通用多模態(tài)大語言模型(Multi-modal Large Language Models,簡稱MLLMs)在自然圖像領域取得了顯著成功。然而MLLMs在遙感領域的發(fā)展仍處于起步階段。為填補這一空白,毛雪瑞教授團隊提出了EarthGPT遙感通才模型,將多傳感器圖像理解和多種遙感視覺任務都無縫集成在同一個框架中。EarthGPT可在自然語言指令下,實現(xiàn)光學、合成孔徑雷達(SAR)圖像和紅外圖像的理解,完成遙感場景分類、圖像描述、視覺問答、目標描述、視覺定位和目標檢測等多種任務(圖1)。

圖1 EarthGPT可通過自然語言交互的方式,完成多傳感器遙感圖像解譯和多視覺推理任務
遙感通才模型EarthGPT包括三項關鍵技術(shù):(1)視覺增強感知機制,通過混合專家編碼器提煉視覺粗粒度語義信息和細粒度感知信息。(2)跨模態(tài)交互理解方法,基于大規(guī)模自然圖像數(shù)據(jù)集做預訓練,賦予大語言模型基本的圖像理解能力和多輪對話能力。(3)統(tǒng)一指令微調(diào)方法,在本文構(gòu)建的遙感多模態(tài)指令數(shù)據(jù)集MMRS-1M(含100萬圖像-文本對)上做微調(diào),實現(xiàn)遙感場景下的綜合圖像解譯能力(圖2)。
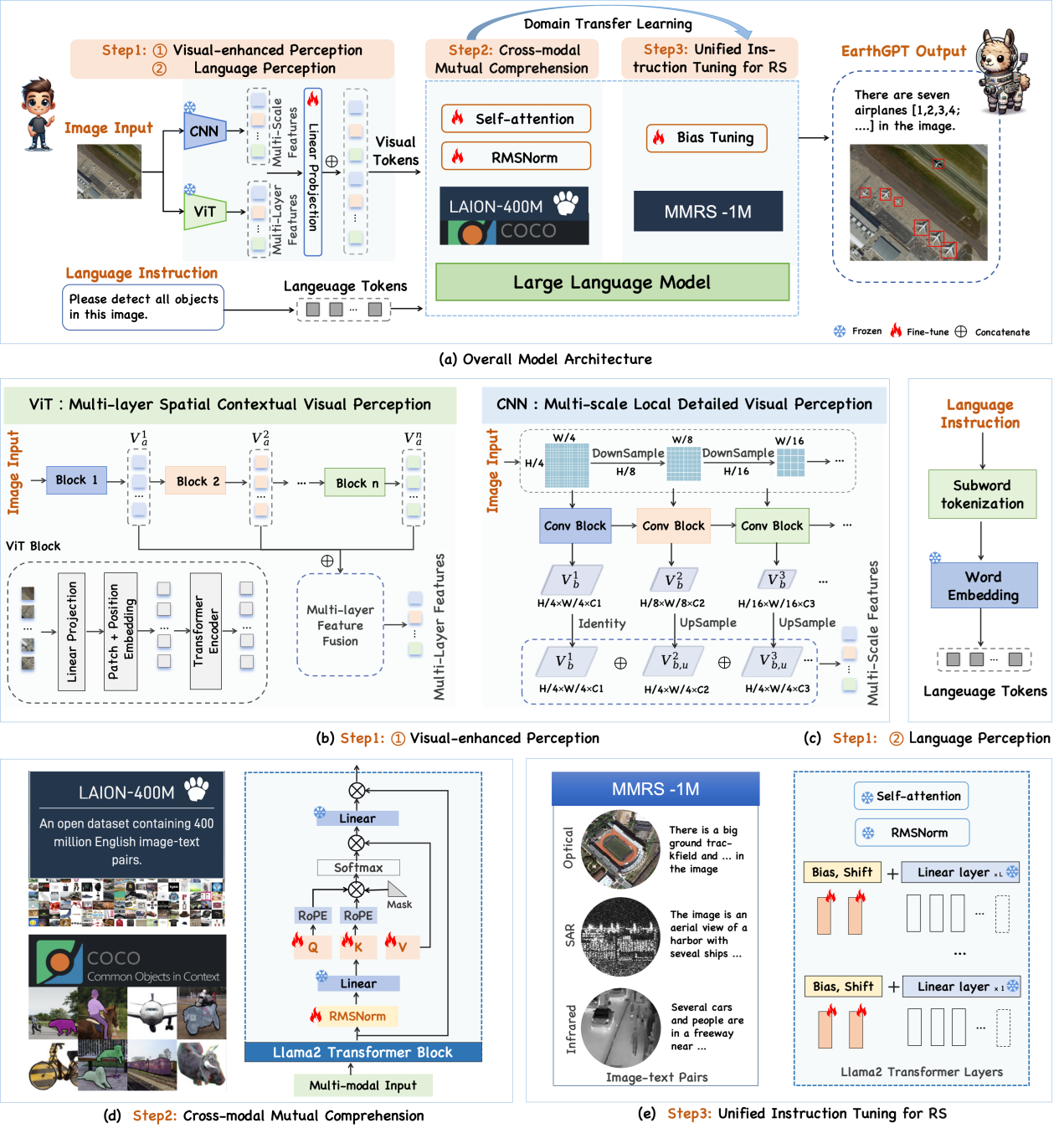
圖2 EarthGPT模型架構(gòu)圖
EarthGPT具備“多才多藝”的遙感視覺解譯能力和多傳感器圖像理解能力,且表現(xiàn)出了卓越的開放域推理能力。該研究貢獻了一個通用的多模態(tài)多任務推理框架和目前最大的MMRS-1M遙感多模態(tài)指令數(shù)據(jù)集,展示出了極大的工業(yè)界實際應用的潛力。
此項工作以北京理工大學為唯一通訊單位,得到了國家自然科學基金的支持。
論文鏈接:https://ieeexplore.ieee.org/document/10547418
分享到: